오늘은 웹 크롤링을 해보려 합니다.
위키백과에서 세계 각 나라별 수도 정보에 대해 가져와 엑셀에 정렬해보겠습니다.
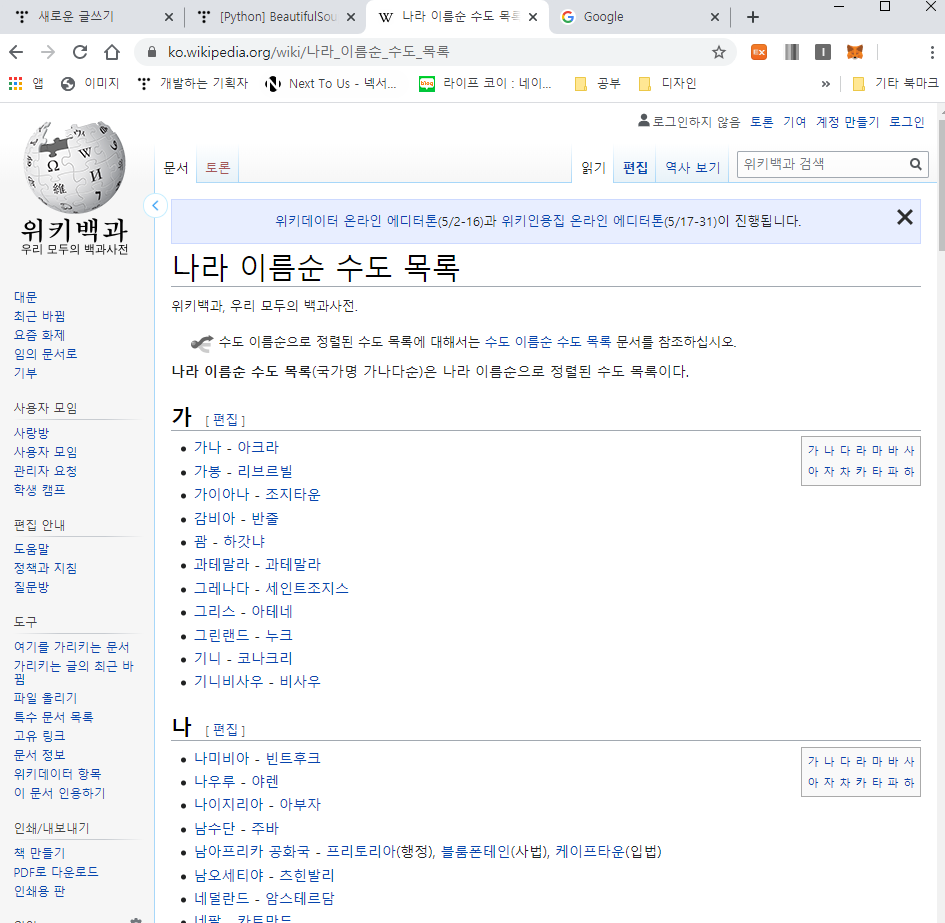

각자 에디터를 열어 '.py'로 끝나는 파이썬 파일을 만들어 주세요.
1. 홈페이지 열기
우선 홈페이지부터 열어야겠죠?
상단에 urlopen 라이브러리를 넣어준 후, 다음과 같이 코드를 넣어주면 url을 에디터에 불러올 수 있습니다.
from urllib.request import urlopen
#url 불러오기
html = urlopen("https://ko.wikipedia.org/wiki/%EB%82%98%EB%9D%BC_%EC%9D%B4%EB%A6%84%EC%88%9C_%EC%88%98%EB%8F%84_%EB%AA%A9%EB%A1%9D")
2. BeautifulSoup html에서 데이터 가져오기
이제 가져온 url에서 html만 빼내 오는 작업을 하려 합니다.
BeautifulSoup를 이용해서 진행할 건데요-,
BeautifulSoup는 html에서 데이터를 추출할 수 있도록 도와주는 라이브러리입니다.
혹시 설치한 적 없으시다면, 터미널에서 설치부터 해주세요.
pip install BeautifulSoup그 후 BeautifulSoup를 import 해주세요.
from bs4 import BeautifulSoup
이제 아까 불러온 url에서 html을 파싱하는 코드를 적어주면 됩니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
#url 불러오기
html = urlopen("https://ko.wikipedia.org/wiki/%EB%82%98%EB%9D%BC_%EC%9D%B4%EB%A6%84%EC%88%9C_%EC%88%98%EB%8F%84_%EB%AA%A9%EB%A1%9D")
bsObject = BeautifulSoup(html, "html.parser") #html 정보 가져오기
3. html에서 특정 부분 불러오기
자, 이제 가져온 html에서 내가 원하는 정보를 가져와야 하는데요.
저는 '가나- 아크라'부분들의 정보를 가져 오고 싶다고 했었잖아요?
그러면 이제 내가 가져오고 싶은 내용들을 담고 있는 공통된 css 선택자를 찾아봐야 합니다.
태그, 클래스, 아이디를 보며 내가 가져 오고 싶은 내용이 공통적으로 어떤 선택자를 가지고 있는지 봐야한다는 거죠.
혹, 무슨 말인지 잘 모르겠어도 우선 따라와주세요:-)
css 선택자 개념이 필요하지만, 잘 몰라도 실습하다보면 조금은 감이 잡힐 거에요!
이때 우리가 필요하다고 느끼는 부분의 선택자 정보는 개발자 도구를 통해 확인할 수 있습니다.
자, 다시 위키로 가서 f12(개발자 도구)를 눌러주시면
다음 화면을 보실 수 있습니다.

이 개발자 도구에서는 홈페이지가 어떻게 코드로 짜여 있는지 확인할 수 있습니다.
내가 원하는 부분의 코드를 알기 위해
개발자 도구에서 좌측 위에 마우스 같이 생긴 친구를 눌러주세요.

그 후 내가 화면에서 궁금한 곳을 클릭해주세요.

그러면 개발자 도구 창이 이렇게 바뀌는 걸 볼 수 있을 거예요.

자, 여기서 중요합니다.
크롤링을 할 때는 '가나-아쿠라.'를 둘러싼 선택자를 선택해서, 정보를 가져올 수 있는데요.
저는 mw-parser-output라는 class 값을 가지고 있는 div 태그 안에 있는 ul 태그 아래에 있는
li 태그를 가지고 와서 값('가 나-아쿠라.')을 가져오기로 결심했습니다.

이때 select 함수를 이용하면 css 선택자로 정보를 가져올 수 있습니다.
bsObject.select('태그명')
bsObject.select('.클래스명')
bsObject.select('#아이디명')
bsObject.select('상위태그명 > 하위태그명 > 하위태그명')
bsObject.select('상위태그명.클래스명 > 바로아래하위태그명.클래스명') #바로 아래 하위태그 시 '>'
bsObject.select('상위태그명.클래스명 하위태그명') #자손 태그 시 띄어쓰기로 구분
bsObject.select('상위태그명 > 바로아래하위태그명 하위태그명')
bsObject.select('태그명.클래스명')
bsObject.select('#아이디명 > 태그명.클래스명)
bsObject.select('태그명[속성=값]')위에 것을 이용하여 여러 css 선택자를 통해 가져올 수 있는데요.
이를 코드로 표현하면 다음과 같은데요.
li_code=bsObject.select('div.mw-parser-output>ul>li')#태그까지 포함한 값이 보임
그러면 이렇게 li 태그 안에 있는 html 정보를 가져올 수 있습니다.

자 그러면 이제는 코드 안에 값, content만 가져오면 되겠죠?
#content만 보기 위해서
ulli_total=[]
for c in range(0,len(li_code)-1):
ulli_total.append(li_code[c].get_text()) .get_text()는 태그들을 없애주고 값만을 빼내 주는 친구예요:-).
요걸 또 실행시켜보면- 아주 예쁘게 나라-수도 값을 가져온 것을 확인할 수 있습니다.

자 이제 엑셀로 요 아이를 넣기 위해서는 나라, 수도라는 각각의 열로 들어갈 수 있게
하나로 붙어있는 '가나 - 아크라'를
서로 떼어내어 ['가나', '아크라']로 바꿔 줘야 합니다.
이는 split 함수를 이용해주시면 되는데요-.
#"나라, 수도"로 정렬시키기
data=[]
for a in range(0,len(ulli_total)):
if ' - ' in ulli_total[a]:
data.append(ulli_total[a].split(' - ')) #나라, 수도가 분리되어 정렬되도록 만드는 작업split함수를 완료한 걸 data라는 변수에 넣어줍니다.
그 후 data를 print해서 확인하면-,
짠! 그러면 열이 분리되어 보이는 것을 알 수 있습니다.

4. 엑셀 변환
이제 마지막으로 엑셀로 변환시키는 작업만 남았습니다.
이때 판다스를 써줘야 하기 때문에, 판다스를 import 해줘야 합니다.
import pandas as pd
그리고는 코드 두 줄을 추가해주면 되는데요.
df=pd.DataFrame(data,columns=["나라","수도"]) # 엑셀에 data 넣을 방식
df.to_csv('country.csv',index=False,encoding="utf-8") #엑셀 변환자 잘 정리한 data를 표형식으로 바꾸어 줄 차례입니다.
DataFrame 함수는 리스트인data 값을 차례로 넣어줍니다.
뒤에 붙은 columns 열의 제목을 적어주는 코드이고요.

그 후 완성한 표를 엑셀로 변환시켜 주는 것이 .to_csv 함수입니다.
그러면 이제 코드가 완성되었는데요!!!
이제 실행시킨 후
에디터를 만들었던 폴더에 가보면 'country.csv'라는 파일이 만들어졌다는 걸 확인할 수 있을 거예요:-)!
가서 파일을 열어보면 잘 정돈되어있겠죠?!!

그런데 한 번씩 이런 알 수 없는 말들이 가득 찬 엑셀 파일이 맞아줄 때가 있는데, 이는 csv 파일로 인코딩하면서
한글을 읽지 못한 경우입니다.

이럴 땐 당황하지 말고 구글로 가서, 스프레드 시트로 방금 파일을 열어주면,
아주 잘 정렬된 것을 확인할 수 있을 거예요~~~:)

5. 결과
앞서 했던 것을 모두 합친 결과 코드입니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
html = urlopen("https://ko.wikipedia.org/wiki/%EB%82%98%EB%9D%BC_%EC%9D%B4%EB%A6%84%EC%88%9C_%EC%88%98%EB%8F%84_%EB%AA%A9%EB%A1%9D")
#url 불러오기
bsObject = BeautifulSoup(html, "html.parser") #html 정보 가져오기
li_code=bsObject.select('div.mw-parser-output>ul>li')#태그까지 포함한 값이 보임
#content만 보기 위해서
ulli_total=[]
for c in range(0,len(li_code)-1):
ulli_total.append(li_code[c].get_text())
print(ulli_total)
#"나라, 수도"로 정렬시키기
data=[]
for a in range(0,len(ulli_total)):
if ' - ' in ulli_total[a]:
data.append(ulli_total[a].split(' - ')) #나라, 수도가 분리되어 정렬되도록 만드는 작업
print(data)
df=pd.DataFrame(data,columns=["나라","수도"]) # 엑셀에 data 넣을 방식
df.to_csv('country.csv',index=False,encoding="utf-8") #엑셀 변환
댓글